Accuracy and Loss Congruency
12 Aug 2021
In the process of familiarizing myself with PyTorch (up until this point I had primarily been using TensorFlow) I decided to make a short post about the relationship between accuracy and loss metrics. All the code used in this post is hosted on github.
Using the popular CIFAR10 dataset, I trained a small, four layer fully connected network. Below is a plot of its performance during training without any regularization. 1.0 represents 100% accuracy on the 10 different image categories.
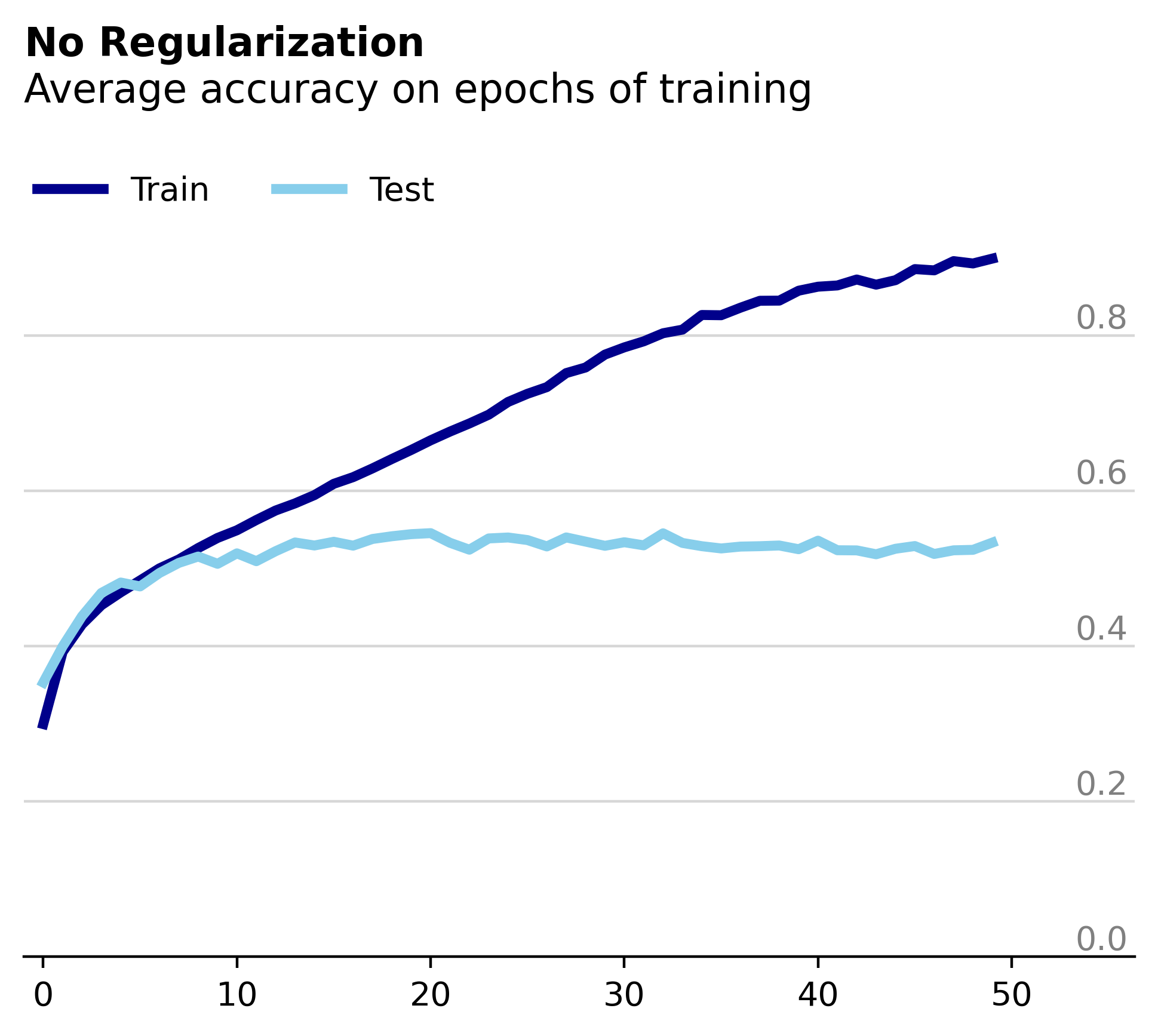
Obviously not the most impressive performance but thats not really what we're going for here. Things get more interesting if we look at the corresponding loss plot.
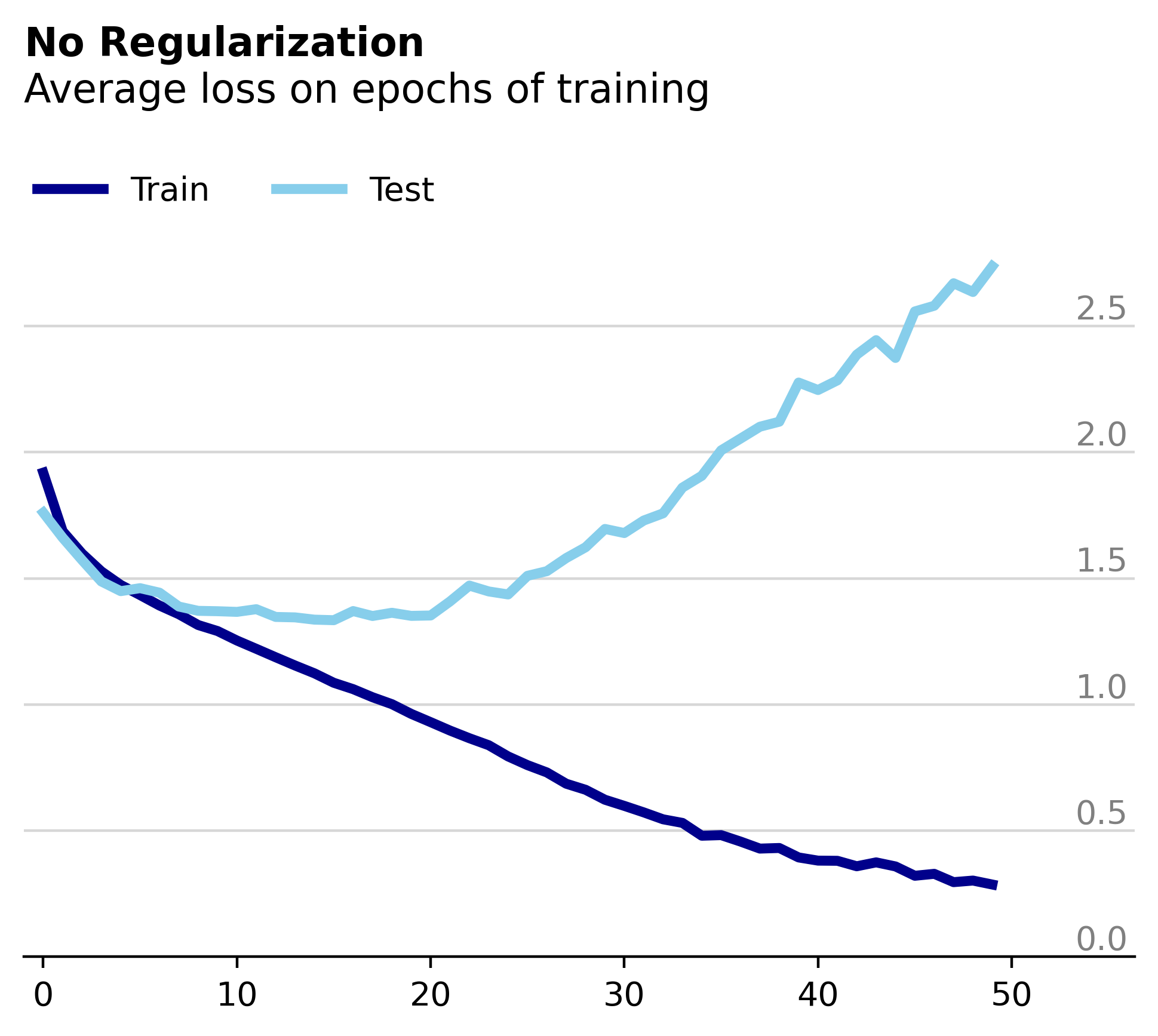
We can see that we are overfitting to the training data, as expected given the lack of regularization. Interestingly, despite the rapidly increasing test loss after the 20th epoch, the model's accuracy on the test set remains steady around 50%. In the figures below we see that even after 200 epochs of training the test accuracy remains constant despite the rapidly increasing test loss.
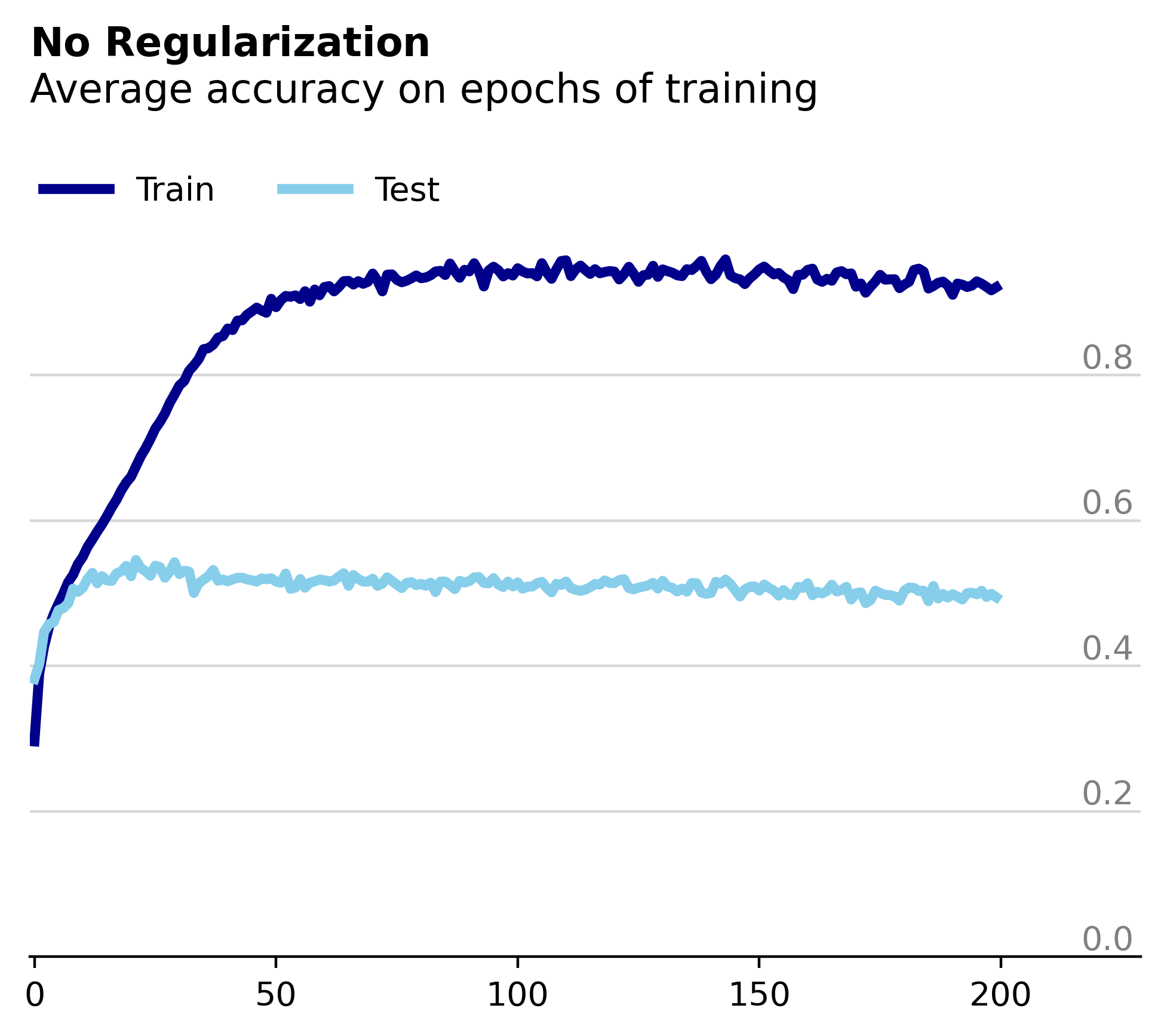
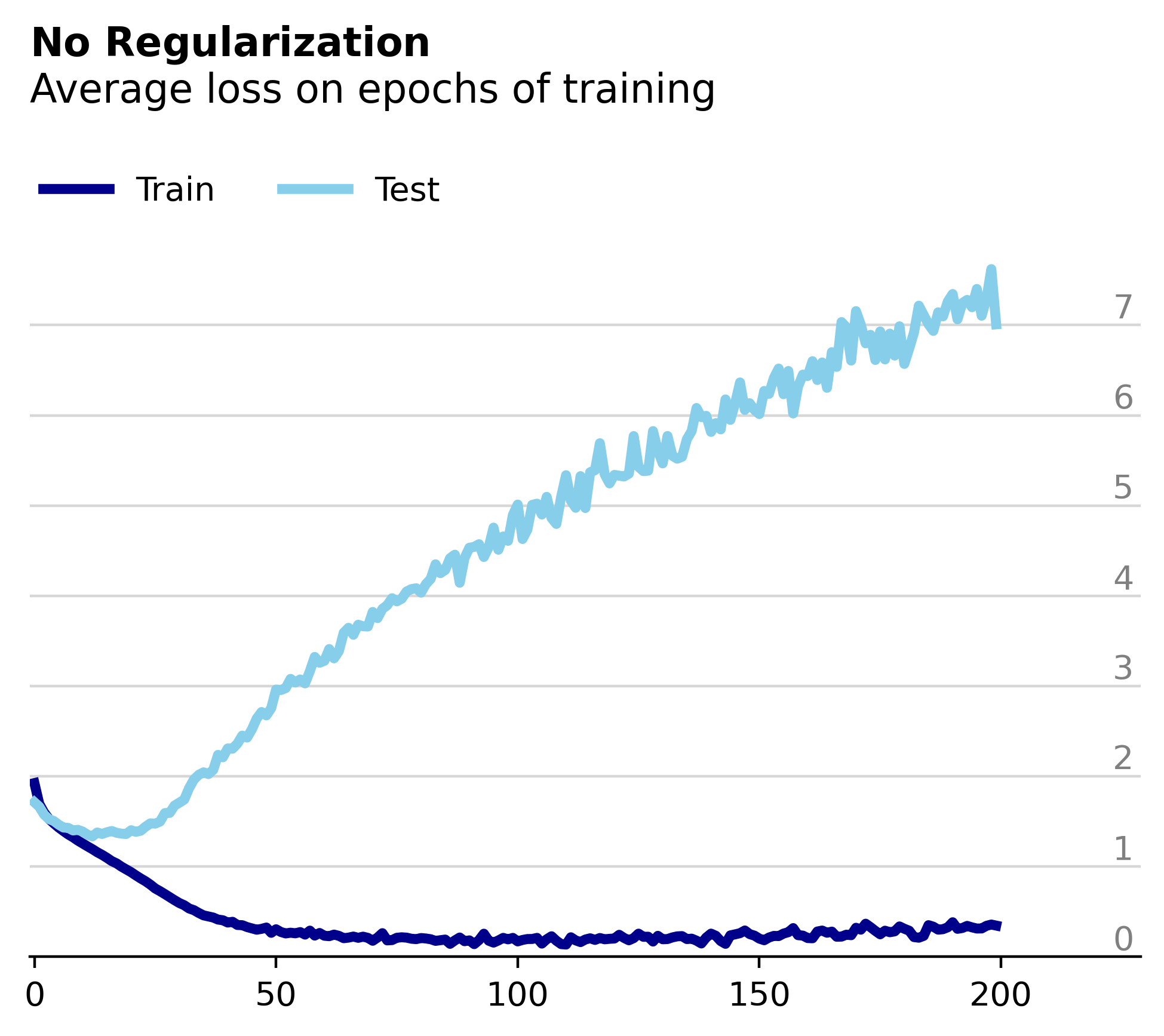
Typically, we interpret loss and accuracy to be inversely correlated - as the model’s loss decreases you expect its accuracy to increase. The above results show that under certain circumstances, this expectation can be deceiving. The fact that loss is calculated on raw prediction values whereas accuracy is based on their threshold hints at a possible source for this discrepancy.
More specifically, if we assume that the model gets the same images right each time its evaluated on the test dataset then there are only two possibilities for the increasing test loss: either the model’s correct predictions get more wrong, but not wrong enough to cross the threshold that would result in a misclassification, or its incorrect predictions get more wrong. Given that the first option is bounded by the misclassification threshold, there is much more room to increase the loss with the second option. Therefore, I would guess that much of the test loss increase can be attributed to the model getting the wrong images more wrong. Especially since after 200 epochs of training the test loss has increased by a factor of five while the test accuracy remains constant.
To definitively tell whether one or the other or both are occurring, further investigation would be necessary. Regardless, this small example shows how much possibility there is for discrepancy between loss and accuracy metrics.